Nova_baremetal_driver深入分析 regexisart
如需转载,请标明原文出处以及作者
陈锐 RuiChen @kiwik
2013/12/04 17:01:07
这里再提供一个 google doc 的共享地址here
简介
Nova BareMetal,我的理解就是通过OpenStack API像管理虚拟机一样管理物理服务器(包括未装OS和安装OS的物理服务器),可以理解为如下对应方式:
| VM | Baremetal |
| 创建虚拟机 | PXE启动,加载操作系统 |
| 启动虚拟机 | 上电 |
| 停止虚拟机 | 下电 |
| 重启虚拟机 | 重启服务器 |
当前的形式是一个Nova Driver和KVM、XEN、Vmware在Nova中同属一层的代码结构。当前Baremetal Driver分为两部分:NodeDriver和PowerManager,NodeDriver的实现有PXE、Tilera; PowerManager的实现有IPMI、Tilera_PDU、Iboot、VirtualPower。这篇文档就介绍大家最熟悉的PXE+IPMI。
Nova BareMetal Driver从OpenStack Grizzly版本加入,当前已经从Nova中分离出来,成为一个 孵化项目Ironic,社区计划Ironic成熟之后,BareMetal就从中Nova中废弃。在Havana版本中 的Nova v3 API已经不支持baremetal的扩展,baremetal的扩展API仅在v2 API中出现。
术语表
-
compute host:部署了nova-compute进程的host
-
baremetal node:被compute host控制的物理节点,当用户创建一个baremetal instace时,compute host在baremetal node上创建一个baremetal instance。
-
baremetal instance:对应为nova的vm instance,直接根据用户指定的image,通过PXE加载操作系统,通过IPMI管理baremetal node的上下电。
-
deploy image:是一个特殊的kernal和ramdisk,是PXE启动需要的,用来将用户指定的image从compute host写入baremetal node。需要在compute host的nova.conf中配置deploy_kernel和deploy_ramdisk,作为scheduler的依据。
-
enrolled:baremetal node注册,通过Nova扩展接口,将baremetal node的mac、CPU、存储和disk的规格注册在baremetal db中,注册参数还包括IPMI的IP、用户和密码。
BareMetal的使用限制
当前需要在nova-compute host上启动dnsmasq作为PXE启动需要的dhcp服务,neutron-dhcp需要停止,以便neutron-dhcp不会响应baremetal node PXE启动时的dhcp请求。这个问题说是在Havana版本中会修复。
当前支持的baremetal Driver的接口:spawn、reboot、destroy、power_on、power_off、attach_volume、detach_volume、plug_vifs。
使用场景
TripleO所希望达到的通过OpenStack部署OpenStack的步骤如下:
-
通过一个包括CMS(配置管理软件统puppet/chef/salt/etc)的镜像部署一个中心节点,后续由CMS决定哪些baremetal node应该安装哪些OS和软件,通过baremetal或Ironic部署物理服务器。
-
将应用软件(OpenStack等)预先安装在cloud-image里,CMS作为安装后配置。
-
将KVM和nova-compute预先安装至cloud-image里,然后通过baremetal PXE加载这个nova-compute镜像,安装出来的baremetal instance就是nova-compute节点,同理制作neutron,cinder等节点镜像,然后部署。
-
使用Heat对于整个云做编排。
-
将baremetal nova-compute和KVM nova-compute在同一个云下管理,使用相同的nova API,共享keystone和glance,通过tenant隔离baremetal和KVM。
使用BareMetal Driver的流程
-
需要先有一套OpenStack环境,可以是一个All-in-one的虚拟机化部署,需要有nova-compute进程。
-
修改nova的配置文件,wiki原文中说如下的配置都需要加入nova-compute host,但是明显scheduler_host_manager、ram_allocation_ratio和reserved_host_memory_mb应该在scheduler节点配置,其他配置项加入nova-compute host。
[DEFAULT] scheduler_host_manager = nova.scheduler.baremetal_host_manager.BaremetalHostManager firewall_driver = nova.virt.firewall.NoopFirewallDriver compute_driver = nova.virt.baremetal.driver.BareMetalDriver ram_allocation_ratio = 1.0 reserved_host_memory_mb = 0 [baremetal] net_config_template = /opt/stack/nova/nova/virt/baremetal/net-static.ubuntu.template tftp_root = /tftpboot power_manager = nova.virt.baremetal.ipmi.IPMI driver = nova.virt.baremetal.pxe.PXE instance_type_extra_specs = cpu_arch:{i386|x86_64} sql_connection = mysql://{user}:{pass}@{host}/nova_bm -
在nova-compute host安装IPMI和PXE需要的软件dnsmasq ipmitool open-iscsi syslinux。
-
为了支持PXE需要配置pxelinux.0引导程序、pxelinux.cfg和tftp的boot根目录。PXE相关内容可以参考here
sudo mkdir -p /tftpboot/pxelinux.cfg sudo cp /usr/lib/syslinux/pxelinux.0 /tftpboot/ sudo chown -R $NOVA_USER /tftpboot sudo mkdir -p $NOVA_DIR/baremetal/dnsmasq sudo mkdir -p $NOVA_DIR/baremetal/console sudo chown -R $NOVA_USER $NOVA_DIR/baremetal -
当前使用Baremetal,至少需要keystone、nova、neutron、glance、nova-compute、dnsmasq和nova-baremetal-deploy-helper这些服务。
# Start dnsmasq for baremetal deployments. Change IFACE and RANGE as needed. # Note that RANGE must not overlap with the instance IPs assigned by Nova or Neutron. sudo dnsmasq --conf-file= --port=0 --enable-tftp --tftp-root=/tftpboot \ --dhcp-boot=pxelinux.0 --bind-interfaces --pid-file=/var/run/dnsmasq.pid \ --interface=$IFACE --dhcp-range=$RANGE上面dnsmasq的启动参数中包括了pxe启动的引导程序pxelinux.0和部署镜像的tftp根目录位置/tftpboot。这里为了避免neutron-dhcp相应PXE启动的dhcp请求,neutron-dhcp需要停止。
-
在msyql中为baremetal创建独立的nova_bm数据库schema,与nova schema分开,nova-baremetal-manage db sync
-
准备镜像,通过openstack社区提供的diskimage-builder创建镜像
git clone https://github.com/openstack/diskimage-builder.git cd diskimage-builder # build the image your users will run bin/disk-image-create -u base -o my-image # and extract the kernel & ramdisk bin/disk-image-get-kernel -d ./ -o my -i $(pwd)/my-image.qcow2 # build the deploy image bin/ramdisk-image-create deploy -a i386 -o my-deploy-ramdisk -
将这些镜像文件上传至glance
glance image-create --name my-vmlinuz --public --disk-format aki < my-vmlinuz glance image-create --name my-initrd --public --disk-format ari <my-initrd glance image-create --name my-image --public --disk-format qcow2 --container-format bare \ --property kernel_id=$MY_VMLINUZ_UUID --property ramdisk_id=$MY_INITRD_UUID <my-image glance image-create --name deploy-vmlinuz --public --disk-format aki <vmlinuz-$KERNEL glance image-create --name deploy-initrd --public --disk-format ari <my-deploy-ramdisk.initramfs -
在nova中创建baremetal专用的flavor,其中cpu_arch、deploy_kernel_id和deploy_ramdisk_id要和compute host的nova.conf中的deploy_kernel、deploy_ramdisk和instance_type_extra_specs配置一致
instance_type_extra_specs = cpu_arch:{i386|x86_64} deploy_kernel = $DEPLOY_VMLINUZ_UUID deploy_ramdisk = $DEPLOY_INITRD_UUID -
创建nova的flavor
nova flavor-create my-baremetal-flavor $RAM $DISK $CPU # cpu_arch must match nova.conf, and of course, also must match your hardware nova flavor-key my-baremetal-flavor set \ cpu_arch={i386|x86_64} \ "baremetal:deploy_kernel_id"=$DEPLOY_VMLINUZ_UUID \ "baremetal:deploy_ramdisk_id"=$DEPLOY_INITRD_UUID -
将物理服务器信息注册到环境中,hostname、mac、cpu、ram、disk信息和IPMI的IP、user、password,然后将服务器的所有网络接口也注册进环境
nova baremetal-node-create --pm_address=... --pm_user=... --pm_password=... \ $COMPUTE-HOST-NAME $CPU $RAM $DISK $FIRST-MAC nova baremetal-interface-add $ID $MAC
Baremetal driver的创建虚拟机流程
- 流程图
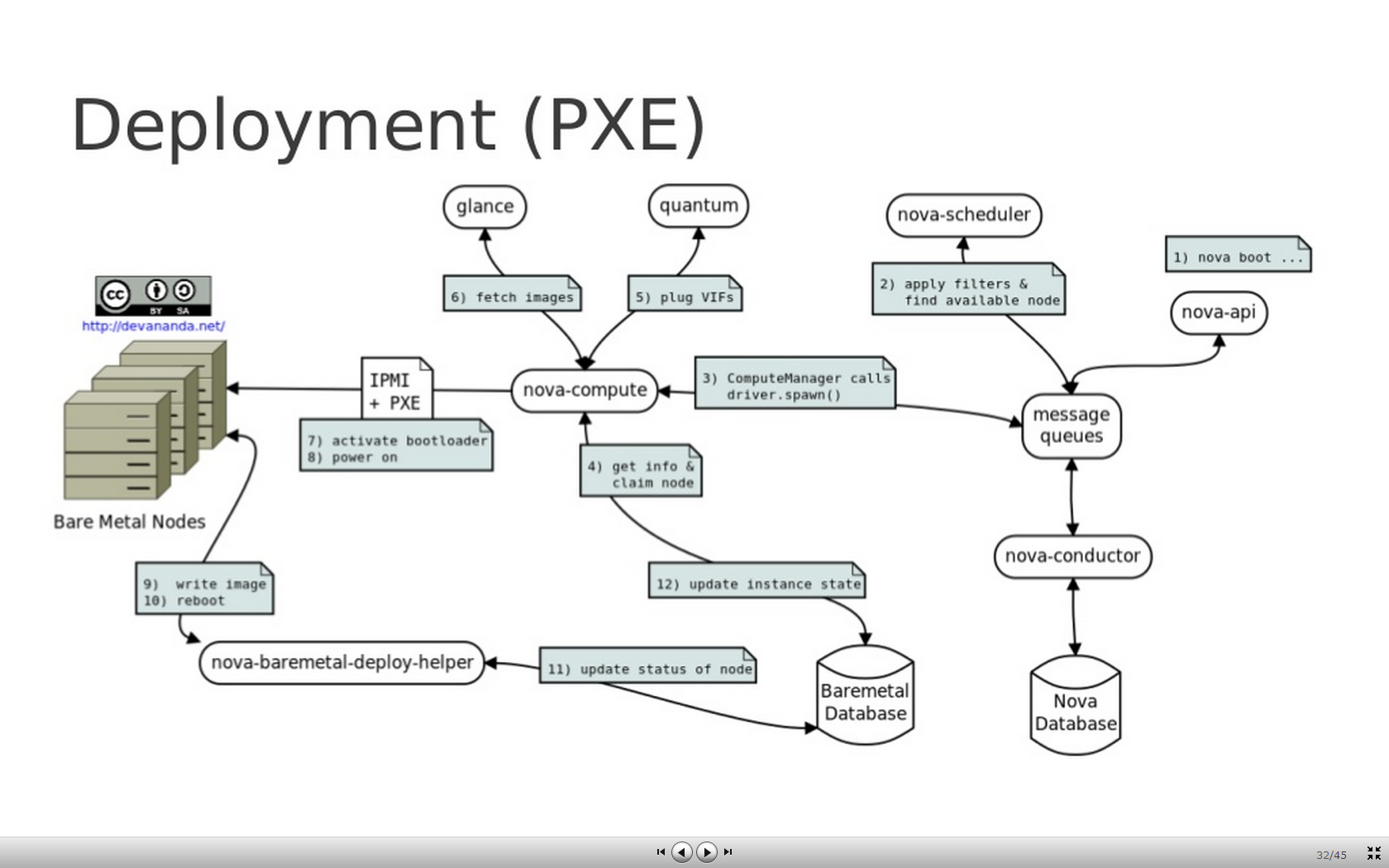
-
首先根据正常nova boot创建instance, flavor为创建的baremetal专用flavor,image为baremetal image。
-
nova-scheduler配置为BaremetalHostManager,这个类继承自default的HostManager,所以可以同时处理vm和baremetal的scheduler,nova-compute host的
nova.conf中配置的[baremetal]选项中的instance_type_extra_specs会被刷新到NodeStats中,当创建instance的flavor的extra_specs根据默认配置的ComputeCapabilitiesFilter找到符合配置的nova-compute host将请求发送到这个baremetal nova-compute host。 -
请求进入nova-compute host因为配置的是BareMetalDriver,进入spawn方法开始创建baremetal instance,根据scheduler选择的instance[‘node’]的uuid查询nova_bm库,将instance_uuid和instance.hostname更新到数据库,然后作如下动作:
-
_plug_vifs 将neutron分配的网络uuid和注册的pif关联
-
_attach_block_devices 将cinder块设备通过iscsi导出到nova-compute host,貌似是通过compute host桥接到baremetal node
-
_start_firewall 配置的是NoopFirewallDriver所以什么都不做
-
cache_images 从instance_type中导出kernel_id、ramdisk_id、deploy_kernel_id和deploy_ramdisk_id,从glance下载对应的image文件保存在tftpboot目录下的按照instance_uuid划分的子目录中,并将qcow2镜像转化为raw镜像
-
activate_bootloader 生成pxelinux.cfg文件,用baremetal的mac地址区分不同的配置,同时可以通过neutron生成的网络信息,配置baremetal node的网络,此功能可配置
-
power_off
-
power_on 通过IPMI重启触发PXE流程
-
activate_node 等待PXE部署完成
-
if失败清除以上动作
-
-
细心的听众可能发现了,哪怎么知道PXE已经部署结束了呢?这里就要用到
nova-baremetal-deploy-helper进程了。nova-baremetal-deploy-helper服务启动之后,会在nova-compute host的10000端口启动一个http监听。当给10000端口发送一个POST请求时,nova-baremetal-deploy-helper会根据消息体中的iscsi iqn,将创建虚拟机时的用户指定的image dd到这个iscsi target中,然后创建swap分区等等,最后将PXE的启动方式从deploy改为boot,最后将数据库中baremetal node的状态改为DEPLOYDONE,nova-compute进程通过查数据库就能知道PXE加载完成了。 -
到现在为止还有两个问题没有想通:谁向nova-baremetal-deploy-helper的10000端口发消息?为什么要用iscsi?第一个问题真的是找了很久都没有发现,python代码中没有给10000端口发POST消息的位置,后来还是在一个baremetal的rst文档中发现了一点线索。nova-baremetal-deploy-helper works in conjunction with diskimage-builder’s “deploy” ramdisk to write an image from glance onto the baremetal node’s disks using iSCSI。
-
diskimage-builder也是OpenStack项目下的一个image制作工具,属于TripleO的一部分。这部分了解的不是很多,一个镜像制作工具,可以制作cloudimage和deployimage,在制作镜像的过程中,可以安装需要的软件和脚本,如果没有猜错的话这些都应该叫elements,文档的开始baremetal的image也是通diskimage-builder制作的,还导出了deploy-ramdisk和deploy-kernel,上面那个向nova-baremetal-deploy-helper发送10000 POST消息的脚本就是在deploy-ramdisk中执行的,千辛万苦的终于在github的
diskimage-builder/elements/deploy/init.d/80-deploy的仓库里发现了这样一段代码:if [ -z "$ISCSI_TARGET_IQN" ]; then err_msg "iscsi_target_iqn is not defined" troubleshoot fi t=0 while ! target_disk=$(find_disk "$DISK"); do if [ $t -eq 10 ]; then break fi t=$(($t + 1)) sleep 1 done if [ -z "$target_disk" ]; then err_msg "Could not find disk to use." troubleshoot fi echo "start iSCSI target on $target_disk" start_iscsi_target "$ISCSI_TARGET_IQN" "$target_disk" ALL if [ $? -ne 0 ]; then err_msg "Failed to start iscsi target." troubleshoot fi echo "request boot server to deploy image" d="i=$DEPLOYMENT_ID&k=$DEPLOYMENT_KEY&a=$BOOT_IP_ADDRESS&n=$ISCSI_TARGET_IQN&e=$FIRST_ERR_MSG" wget --post-data "$d" "http://$BOOT_SERVER:10000" echo "waiting for notice of complete" nc -l -p 10000 echo "stop iSCSI target on $target_disk" stop_iscsi_target -
这段代码其实也间接的回答了我的第二个问题,为什么要用iscsi?baremetal node通过deploy ramdisk将disk通过iscsi暴露给了nova-compute host,然后在nova-baremetal-deploy-helper进程中获取baremetal node的disk的iscsi iqn,然后将用户指定的image dd到这个iscsi target中,完成对于baremetal node的系统盘安装,然后给baremetal node的10000端口发一个done的socket消息,通知baremetal node停止iscsi。
以上就是我对于baremetal的一点分析,说实话老外解决问题使用的一些方案,真不是我们轻易可以想得到的。
参考文献
https://wiki.openstack.org/wiki/Baremetal
http://www.slideshare.net/devananda1/ods-havana-provisioning-bare-metal-with-open-stack
https://github.com/openstack/diskimage-builder
http://blog.csdn.net/ruixj/article/details/3772752