Nova如何支持live Upgrade regexisart
如需转载,请标明原文出处以及作者
陈锐 RuiChen @kiwik
2015/4/4 16:35:55
写在最前面:
OpenStack半年一个版本,升级是一个怎么也躲不开的问题,总是在想如何在复杂的OpenStack部署环境中做到业务平滑升级,同时又不影响到用户,当前的OpenStack中又有那些特性支持live-upgrade,今天以Nova作为一个开端,看看Nova中是怎么做的。
代码基线:Kilo
官方文档
如今的OpenStack官方文档已经相对比较全面了,Operations Guide中就有一个章节专门描述了升级相关的指导,并举了几个版本升级的例子,虽然比较简单,但是大体的框架和步骤都已经有了。基本的思路就是:小规模验证 -> 备份配置文件和数据库 -> 更新配置文件 -> 利用包管理器升级安装包 -> 停止进程 -> 更新数据库 -> 启动进程 -> 再次验证。推荐大家都仔细阅读一下。
upgrade levels
官方文档中专门提到了一个概念 upgrade levels,这里涉及到Nova的第一个live-upgrade特性。
先稍微绕开一点,当前由于对象化的引入,nova中的api, scheduler, conductor, compute四个进程都存在循环依赖,所以不可能简单的划分出一个依赖树,从树的叶子节点开始升级,从而保证API兼容性,这种升级的方式在nova中不可行。有循环依赖也就是说,从任何一端开始升级,都有可能发生高版本client向低版本server发送消息的可能。这里就需要用到upgrade levels。
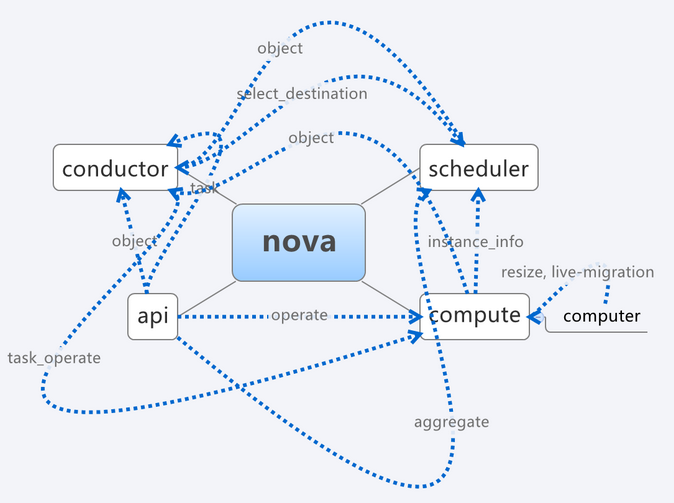
简单来说就是一个rpcapi端的版本控制机制,在升级之前,rpc client端设置一个版本阀值,当rpcapi需要发送消息时,通过can_send_version方法判断,如果超过阀值就做自动降级处理,没有做降级处理的消息,会被禁止发送,具体实现可以参考oslo_messaging的代码。例子如下:
def shelve_offload_instance(self, ctxt, instance,
clean_shutdown=True):
msg_args = {'instance': instance}
if self.client.can_send_version('3.37'):
version = '3.37'
msg_args['clean_shutdown'] = clean_shutdown
else:
version = '3.0'
cctxt = self.client.prepare(server=_compute_host(None, instance),
version=version)
cctxt.cast(ctxt, 'shelve_offload_instance', **msg_args)
如果我们计划从juno升级到kilo,首先需要设置所有rpcapi的upgrade levels为juno,这样当我们升级的过程中,如果一个已经升到kilo版本的conductor向juno版本的compute发送rpc消息,还是会使用和juno版本rpcapi接口兼容的消息。
API序列化
每一个rpcapi的都有版本号,每次的api修改都需要调整版本号,nova通过版本号来判断client侧和server侧是否兼容。
整个rpc调用分为两个步骤,rpcapi侧将整个rpc调用序列化,然后在rpc server也就是manager侧收到消息,再反序列化执行。整个rpc message除了context之外,message字典结构体中还包括四个部分:
- method
- args
- version
- namespace
version标识了rpcapi的版本,在rpc server侧直接通过method名称查找manager中的函数,将args参数反序列化之后,调用method函数执行。调用之前也会在server侧,检查rpcapi的version是否和manager的实现版本兼容,如果不兼容抛出异常。namespace用于区分conductor中的ConductorAPI和ConductorTaskAPI。
可以看到如果我们修改代码,调整了rpcapi的接口参数,就一定要同时更新client/server侧的版本号,并在rpc server的接口实现侧提供参数默认值。
在rpcapi的层面,低版本client调用高版本server,兼容支持;高版本client调用低版本server,通过upgrade levels自动降级,未做自动降级处理的禁止发送,抛出异常。
API参数序列化
除了rpcapi在升级过程中需要考虑升级兼容性,args参数中的NovaObject对象,也需要考虑升级兼容性。所有的NovaObject都有版本号跟踪每一次的修改。
在rpcapi发送消息之前,首先对接口参数进行序列化,如果参数是NovaObject类型,都通过NovaObject的obj_to_primitive方法转化成dict类型之后,保存在args,如果是原始类型,直接保存在args中。rpc server接收到消息之后,将args中的接口参数反序列化,如果是NovaObject对象,通过obj_from_primitive接口反序列化。
NovaObject类中存在一个_obj_classes类属性,其中会保存一个NovaObject的多个版本的实现,通过版本号从大到小排序,最大版本就是当前代码实现版本,较小版本由升级过程中低版本进程发送而来。
NovaObjectSerializer.deserialize_entity用于反序列化对象,如果server端当前实现版本大于发送过来的版本,直接兼容,反序列化对象。如果发送的版本大于server端实现版本,忽略最末端版本号,再次尝试反序列化,如果仍然不能成功,就需要调用conductor.object_backport方法,尝试降级处理,将args参数转化为server端可以处理的object。
升级顺序
升级顺序可能不同人分析有不同的结果,我这里提供一个建议顺序和分析过程。
社区的operation guide中推荐的升级方式为先controller节点,然后compute节点。在我看来,这样升级有一个好处就是可以尽早的发现问题,降低风险和回退成本。controller节点进程最多也最复杂,首先升级可以尽早的发现问题,这时回退也只需要回退controller,如果有100个compute都升级完成了,再升级controller,如果升级失败,就需要回退100个compute节点。
先升级controller有个问题,就是client端的版本要大于server端,也就是4.0的conductor可能调用3.0的compute,需要用upgrade_levels控制。如果compute进行数据库操作,就会执行NovaObject的方法,最后调用到conductor的object_class_action方法,这个方法有特殊处理,会将返回值版本转化为调用端的版本。
综合这几点,推荐的一个升级顺序为:
- conductor
- scheduler
- compute
- api
最后升级api进程的原因是,希望所有新增接口和新增参数能在整个环境都支持的情况下,再提供给用户使用。
升级顺序并无一个定论,每种顺序各有利弊,欢迎讨论。
升级在OpenStack中一直都是一个大问题,没有最佳理论,只有最佳实践,需要不断的尝试总结交流,希望能为OpenStack的升级成熟,尽自己的一份力。